This article is for personal use to review the way to web crawl images from different websites.
Why Image Crawler?
When I was studying object classifiers or detectors using deep learning methods, getting the right images to train was always the laborious part. Even though there are many existing image datasets that can be used, those sometimes did not have the object categories that I wanted or contained so many unnecessary object categories that we did not want to waste time downloading them. Therefore, my solution to this was to crawl images from different search engines, such as Google.
However, those websites usually have special algorithms to block bots from crawling their images too fast since it could burden their servers. And different websites have different ways of image searching. For example, Google has a scroll-based search method where new images pop up when you scroll down, and to see more images, you have to click the "show more" button once in a while. And some other websites have a page-based search method where you have to go to the next page to see more images.
As a result, in this article, I will demonstrate a general solution that can be used for both image searching methods. Of course, we should limit the speed of the crawler so that we do not harm the websites. Also, we should not violate the copyright policy for images. For example, we should not use this for commercial or research purposes but just for simple personal testing. Or you can use this to get images of your favorite idol.
Selenium + Urllib
Python supports a native web crawler called Urllib. For the most part, this is fast and useful. However, to trick websites, we have to use a web browser-based web crawl library called Selenium, which can do realistic scrolling and clicking. To use Selenium, we must first download its Python library and then install its browser driver. For this article, I am using the Chrome driver, but you can use other browser drivers such as Tor, which has more anonymity. The guide for this is in this link. Our strategy to trick a bot detector is like below
- Scroll the page slowly like a human until the page is not scrollable.
: If we scroll too fast, the images do not appear. - Click the "show more" button if there is and resume scrolling.
- Scroll back to the top and come back to the bottom to activate the images that went into sleep mode.
- Search, check, and save image urls
- If there is the next page, go to it and repeat steps 1-4
- Download images from urls
Selenium collects the image urls, and Urllib downloads the images. We divide the task like this because when you try to download images during the searching step, there is a higher chance that websites recognize your bot and start to show some buggy behavior. And the websites usually have no bot prevention system for downloading through their internal image urls, which means that we can do this step faster with Urllib. The code for our strategy looks like this.
from selenium import webdriver
from selenium.webdriver.common.by import By
import urllib.request
import threading
import time
import os
# 1. search engine name
# 2. search engine url (with keyword as {})
# 3. image class name
# 4. image class url checking string
# 5. next page button class name
search_engine = {"naver" : ["https://search.naver.com/search.naver?sm=tab_hty.top&where=image&query={}", "img._image._listImage", "http", ""],
"google" : ["https://www.google.com/search?q={}&source=lnms&tbm=isch&tbs=itp:photo", "img.rg_i.Q4LuWd", "image", ""],
"crowdpic": ["https://www.crowdpic.net/photos/{}&type=JPG", "img", "thumb", ""],
"pixabay": ["https://pixabay.com/images/search/{}/", "img.photo-result-image", "https", ".pure-button"],
"pexels": ["https://www.pexels.com/search/{}/", "img.spacing_noMargin__Q_PsJ", "https", ""],
"unsplash": ["https://unsplash.com/s/photos/{}", "img.tB6UZ", "https", ".EIBBq"],
"shutterstock": ["https://www.shutterstock.com/search/{}?image_type=photo", "img.mui-1l7n00y-thumbnail", "https", ".mui-l1ws68-a-inherit"]}
class Crawler(threading.Thread):
def __init__(self, keyword, engine, directory):
threading.Thread.__init__(self)
# setting crawling speed and quantity limits
self.PAGE_SCROLL_PAUSE = 5 # seconds
self.PAGE_SCROLL_LIMIT = 10 # scrolls
self.PAGE_NEXT_TURNS = 10 # pages
self.keyword = keyword
self.engine = engine
self.directory = directory
# setting selenium web crawler that can fake a bot detector
self.options = webdriver.ChromeOptions()
self.service = webdriver.chrome.service.Service("./chromedriver_win32/chromedriver.exe") # chromedriver directory
self.options.add_argument('headless')
self.options.add_argument("--incognito")
self.options.add_argument("user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64)"
+"AppleWebKit/537.36 (KHTML, like Gecko)"
+"Chrome/87.0.4280.141 Safari/537.36")
self.driver = webdriver.Chrome(service=self.service, options=self.options)
# setting urllib web crawler that can fake a bot detector
opener = urllib.request.build_opener()
opener.addheaders = [('User-agent', 'Mozilla/5.0')]
urllib.request.install_opener(opener)
self.url = search_engine[self.engine][0].format(self.keyword)
self.img_class = search_engine[self.engine][1]
self.checker = search_engine[self.engine][2]
self.next_btn = search_engine[self.engine][3]
self.result = []
self.done = False
def isDone(self):
return self.done
def scroll(self):
self.driver.get(self.url)
end_height = self.driver.execute_script("return document.body.scrollHeight")
start_height = 1
for _ in range(self.PAGE_SCROLL_LIMIT):
# scroll with small steps like human
for i in range(start_height, end_height, 100):
self.driver.execute_script("window.scrollTo(0, {});".format(i))
# create a human-like behavior so that new images get loaded
self.driver.execute_script("window.scrollTo(0, {});".format(end_height-100))
self.driver.execute_script("window.scrollTo(0, {});".format(end_height))
time.sleep(self.PAGE_SCROLL_PAUSE)
# check if the crawler has reached the bottom of the page and click "more images" button
current_height = self.driver.execute_script("return document.body.scrollHeight")
if current_height == end_height:
try:
self.driver.find_element(By.CSS_SELECTOR, ".mye4qd").click()
time.sleep(self.PAGE_SCROLL_PAUSE)
except: break
start_height = end_height
end_height = current_height
# scroll from top to bottom to get all images loaded
for i in range(1, end_height, 400):
self.driver.execute_script("window.scrollTo(0, {});".format(i))
# check image links and add the correct ones to results
candidates = self.driver.find_elements(By.CSS_SELECTOR, self.img_class)
for candidate in candidates:
try:
attribute = candidate.get_attribute('src')
if self.checker in attribute: self.result.append(attribute)
except: pass
def run(self):
print("Crawling started (", str(self.keyword), " ", str(self.engine), ")")
for i in range(self.PAGE_NEXT_TURNS):
self.scroll()
# change the seraching url to the next page button's url
try: self.url = self.driver.find_elements(By.CSS_SELECTOR, self.next_btn)[-1].get_attribute('href')
except: break
self.driver.close()
print("______________________________________")
print("Crawling results (", str(self.keyword), " ", str(self.engine), ")")
print("Total ", len(self.result), " images identified")
print("______________________________________")
if not os.path.isdir('./{}'.format(self.directory)):
os.mkdir('./{}'.format(self.directory))
print("Download started (", str(self.keyword), " ", str(self.engine), ")")
for index, link in enumerate(self.result):
urllib.request.urlretrieve(link,'./{}/{}_{}_{}.jpg'.format(self.directory,self.keyword,self.engine,index))
time.sleep(0.25) # speed down the crawling
print("Download completed (", str(self.keyword), " ", str(self.engine), ")")
self.done = True
a = Crawler("dog", "google", "dog")
b = Crawler("dog", "pixabay", "dog")
c = Crawler("dog", "pexels", "dog")
d = Crawler("dog", "naver", "dog")
e = Crawler("dog", "shutterstock", "dog")
a.start()
b.start()
c.start()
d.start()
e.start()I made two additional improvements to my old code: scalability to be used with different websites and speed using threading. Since we use a lot of delays in the code to mimic human behavior, threading speeds things up a lot if we are trying to get images from different websites. It took about 13 minutes to collect 3,955 dog images. If we delete the time delay, it will be much faster but did not do it since that will cause server problems. If you want to collect more images, increase the scroll and page limits. Also, rather than using one search key word, try to use many similar key words. For example, rather than just searching "dog," try to also search "Husky," "Dobermann," "Golden Retriever," and so on. This is especially useful when crawling from Google, because they limit the number of images for each search.
Duplicates Removal
When you crawl many different websites, there is a higher chance that you will get the same image. In this case, we can use the Python library called "imagededup." The following code detects the duplicate images, and it took 35 seconds to process 3,955 images.
from imagededup.methods import PHash
phasher = PHash()
# Generate encodings for all images in an image directory
encodings = phasher.encode_images(image_dir='./dog')
# Find duplicates using the generated encodings
duplicates = phasher.find_duplicates(encoding_map=encodings)
duplicates = {k: v for k, v in duplicates.items() if v}Below images are sucessful results.

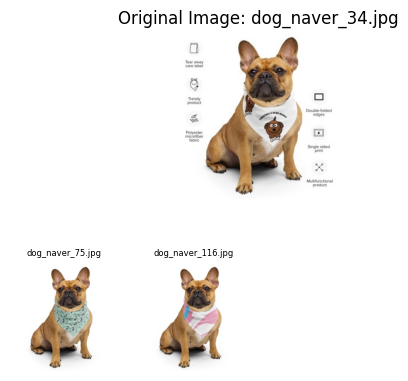
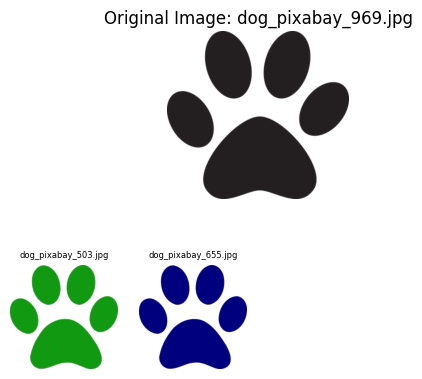
We can see that changes in scale and color and minor modifications are well detected. However, if there is some watermarks on images or images are black and white icons, the algorithm does not work well.

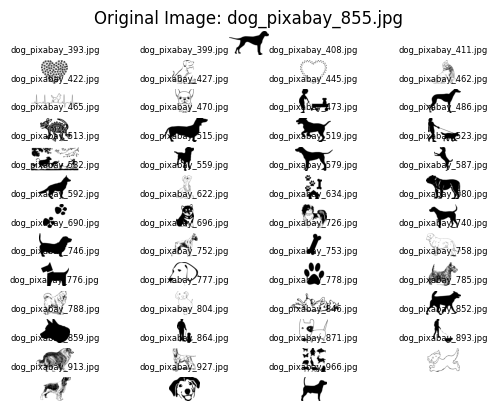
Of course, you can use different methods in the library like CNN deep learning method, but, of course, they come with a slower speed.
'Tech toy' 카테고리의 다른 글
| Color quantization with Self-organizing Map (0) | 2022.11.06 |
|---|